Chapter 10 – General Back Propagation
Chapter 10 – General Back Propagation#
Data Science and Machine Learning for Geoscientists
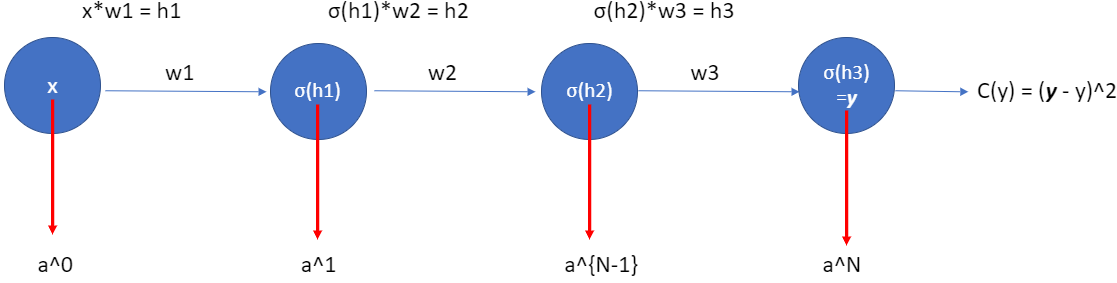 Figure 10.1: The3blue1brown does a pretty good animation already:
https://www.youtube.com/watch?v=tIeHLnjs5U8
Figure 10.1: The3blue1brown does a pretty good animation already:
https://www.youtube.com/watch?v=tIeHLnjs5U8To better understand the general format, let’s have even one more layer…four layers (figure 1.14). So we have one input layer, two hidden layers and one output layer. To simplify the problem, we have only one neuron in each layer (one weight per layer, e.g. \(w_1\),\(w_2\),…), with \(b=0\). And \(C\) is some cost function. The output in the output layer,
where \(N=3\) in this example of figure 10.1.
Therefore we have
where \(a^{(2)} = \sigma(h_2)\), and it determines the cost function (simplified to \(C=(\boldsymbol{y}-y)^2\)). If the actual output \(\boldsymbol{y}\) from the network is close to the desired output \(y\), then the cost will be low, while if it’s far away, the cost will be high.
Also, let’s remember that we have used
to make things simpler.
Note that I use \(w_n\) and \(w^{(N)}\) interchangeably, but they are the same in the single neuron net example. The notation of \(w^{(N)}\) is for a more complicated network we cover later. Anyway, let’s study the gradient \(\frac{\delta C}{\delta w_1}\) associated to the first hidden neuron. If we change the weight \(w_1\) by a tiny nudge \(\Delta w_1\). That will set off a cascading series of changes in the rest of the network. First, it causes a change \(\Delta a_1\) (\(a_1 = \sigma(h_1)\)) in the output from the first hidden neuron. That, in turn, will cause a change \(\Delta h_2\) in the weighted input to the second hidden neuron. Then a change \(\Delta a_2\) in the output from the second hidden neuron. And so on, all the way through to a change \(\Delta C\) in the cost at the output. We have
This suggests that we can figure out an expression for the gradient \(\frac{\delta C}{\delta w_1}\) by carefully tracking the effect of each step in this cascade. To do this, let’s think about how \(\Delta w_1\) causes the output a1 from the first hidden neuron to change. We have \(a_1=\sigma(h1)=\sigma(w_1*x)\), so the change in \(a_1\)
That \(\sigma^{'}(h_1)\) term converts a change \(\Delta w_1\) in the weight into a change \(\Delta a_1\) in the output activation. That change \(\Delta a_1\) in turn causes a change in the weighted input \(h_2=w_2*a_1\) to the second hidden neuron:
Combining our expressions for \(\Delta h_2\) and \(\Delta a_1\), we see how the change in the weight \(w_1\) propagates along the network to affect \(h_2\):
This change in \(h_2\) can result in a change in \(a_2 = \sigma(h2)\):
which will cause a change in \(h_3\).
This change in \(h_3\) will cause a change in \(\sigma(h_3)\), also known as \(\boldsymbol{y}\), the prediction result.
This change in the prediction value \(\boldsymbol{y}\) will cause a change in the cost function, \(\Delta C\), making it bigger or smaller (of course we want it to be as small as possible).
We can keep going in this fashion, tracking the way changes propagate through the rest of the network, in theory to the \(n^{th}\) layer. After dividing \(\Delta w_1\) at the both sides in equation (84), the resulting gradient for the \(w_1\) in this four layers network should be:
Or
We should be reaffirming our idea of defining the `Error Term’ (by figure 10.2) for the efficiency of our code.
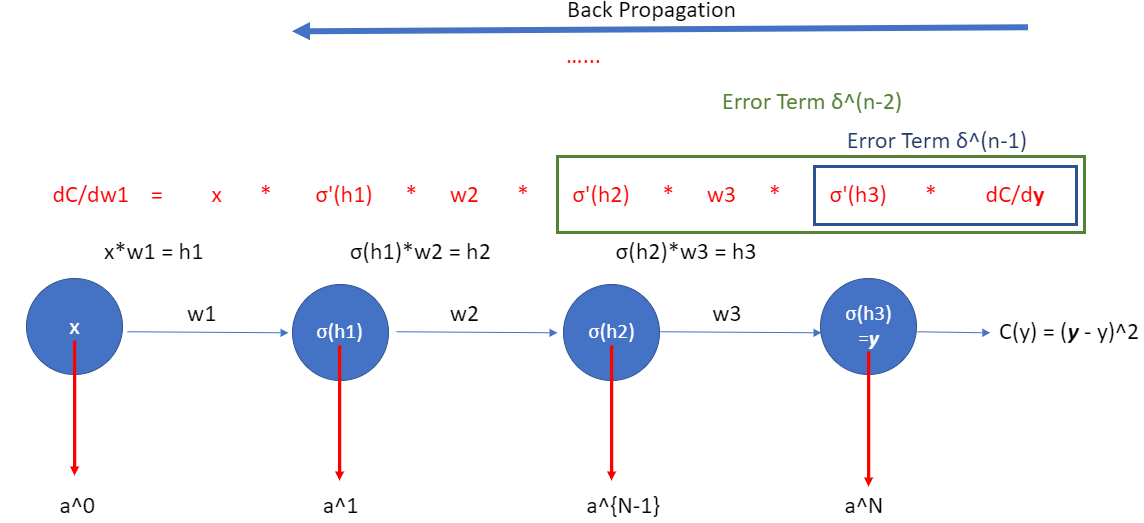 Figure 10.2
Figure 10.2If we take a look at just the last two neurons – \(a^{(N-1)}\) and \(a^{(N)}\), then we have the following:
which is investigating the amount of change of \(C\) due to a tiny nudge of \(a^{(2)}\).
This is helpful because now we can just keep iterating this chain rule idea backwards to see how sensitive the cost to the previous weights and biases.
This is just a little bit more complicated when we have more than one neuron in each layer because we have more indices to keep track of. Let’s take a look at the last two layers in a multiple neuron structure.
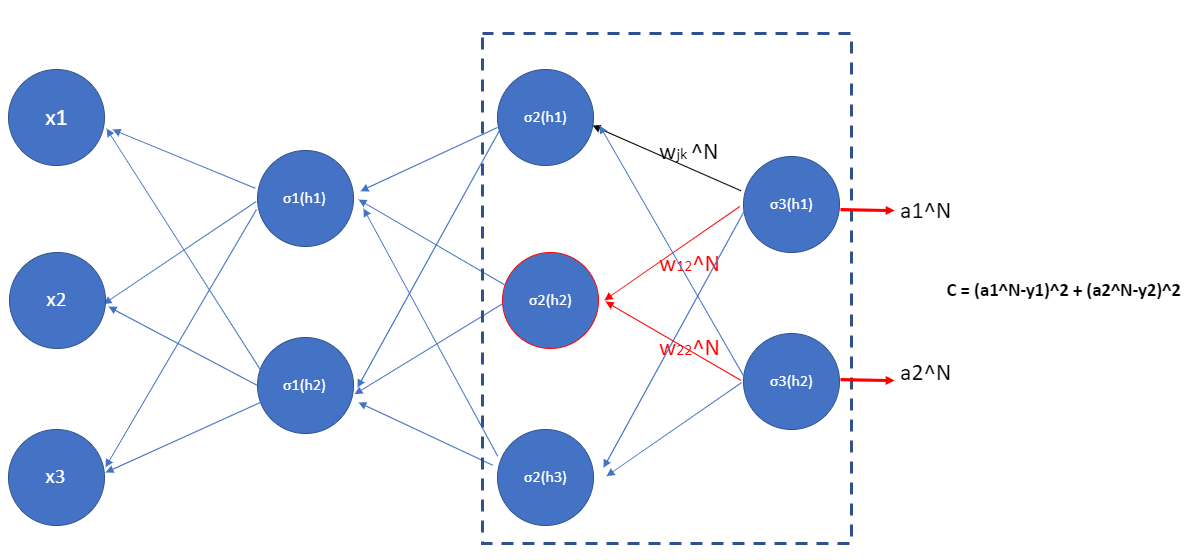 Figure 10.3
Figure 10.3The change of \(h_1^{(3)}\) or \(h_2^{(3)}\) in the output layer will change the cost \(C\), and we define such gradient as \(\delta^{(N)}_j\):
and
or in general
It’s easy to rewrite the equation in a matrix-based form, as
Then, the change in the \(h_j^{(N-1)}\) in the \(N-1\) layer will change \(a^{(N-1)}_j\) and then results in a change in \(a^{(N)}_j\), which will cause the change in the cost \(C\). In specific (red neuron in figure 10.3), we have
Similarly,
and
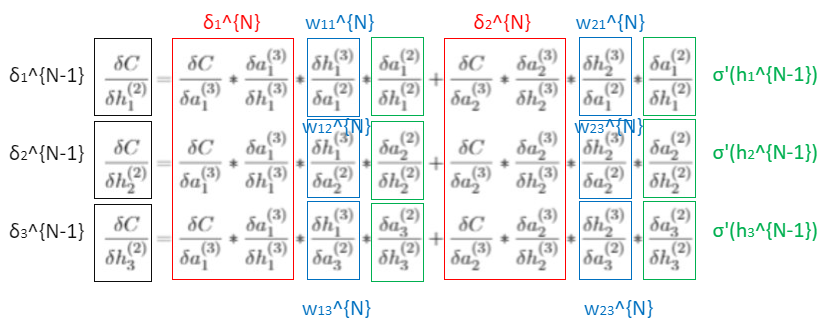
Now, we can define such gradient in equations (92), (93) and (94) by \(\delta^{(N-1)}\) in a vector form with \(\delta^{(N)}\) (shown in figure 10.4)
This in general is the following
where \(\odot\) is the handamard or elementwise product.
We can keep going back (to the left) in the neural network to investigate how the change in \(\sigma_3^{N-2}\) (i.e. \(\sigma_3^{1}\)) can cause a change in \(C\).
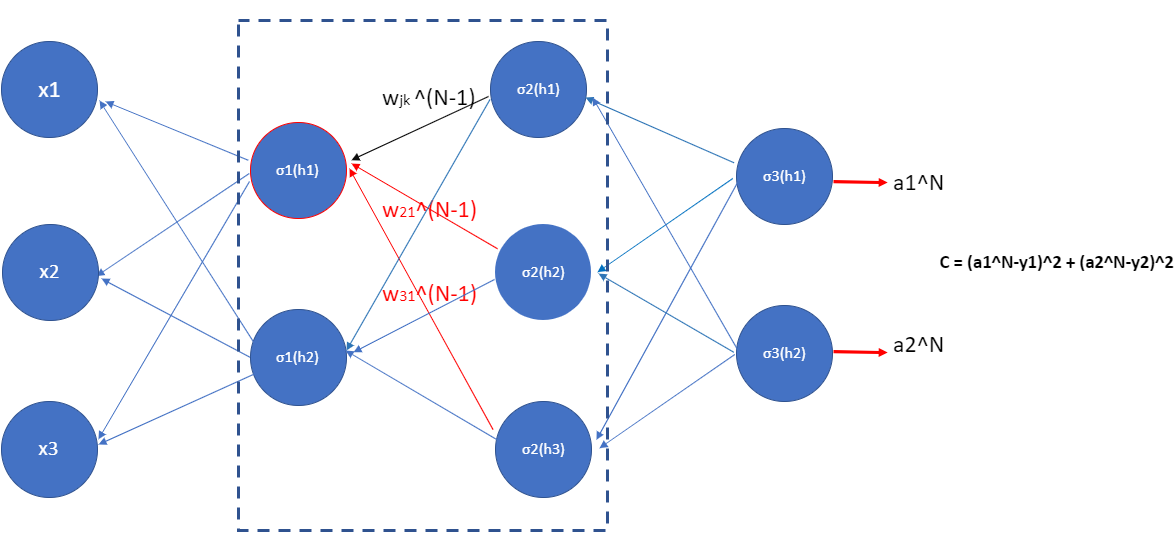 Figure 10.5
Figure 10.5For example, the change of neuron in red circle causes changes of three neurons in the second layer, and then they cause changes in the two neurons the output layer, which change the cost. We also need to consider the change of cost due to the second neuron (i.e. \(\sigma_1(h_2)\)). To express this in a general form:
So we have obtained the change of \(C\) with respect to \(h_i\) in the first layer. Now let us remember the actual goal here is to investigate how the change in weights caused the change in the cost. That’s right, it is the change of weights \(w\) that changes the \(h_i\). This connects with the expression in equation (97): \(\frac{\delta C}{\delta h_i^{1}}\), which leads to the change of \(C\).
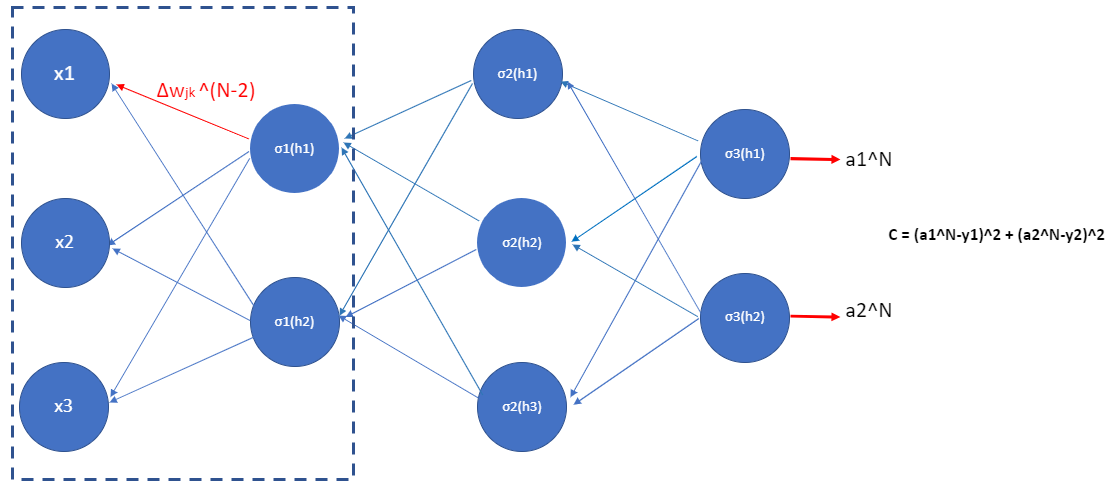 Figure 10.6
Figure 10.6For example, since we know that
Then its derivative wrt. \(w_{11}\) (i.e. \(\frac{\delta h^{(1)}_1}{\delta w_{11}}\)) is just \(x_1\).
Therefore, we can use the chain rule to obtain the change of \(C\) due to the change of \(w_{11}\)
Finally, we can update the weight by using the equation (74) in chapter 9.
Having understood backpropagation in the abstract, we can now understand the code used to implement backpropagation.
def backprop(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))